C++ GMSK Modem Series - Part 1 (PT-BR)
O começo...
Esta é a primeira parte da minha aventura tentando implementar um modem GMSK em C++, observe que ele ainda está em desenvolvimento e provavelmente muitas coisas mudarão entre as postagens conforme eu refatoro parte do código e encontro mais bugs (há muitos, LOL).
GMSK (Gaussian Mínimo Shift Keying) é interessante porque pode ser modulado e demodulado (não coerentemente) como FSK (Frequency Shift Keying), isso simplifica muitas etapas de processamento, modula e demodula o sinal IQ. Outro benefício é que ele tem uma BER (taxa de erro de bit) mais baixa do que o FSK e usa um filtro gaussiano mais simples em vez do filtro de correspondência de cosseno elevado de raiz (Root raised-cosine, RRC) normalmente usado com modulações digitais.
Alguns resultados plotados no GnuRadio (a escala pode variar entre os gráficos…):
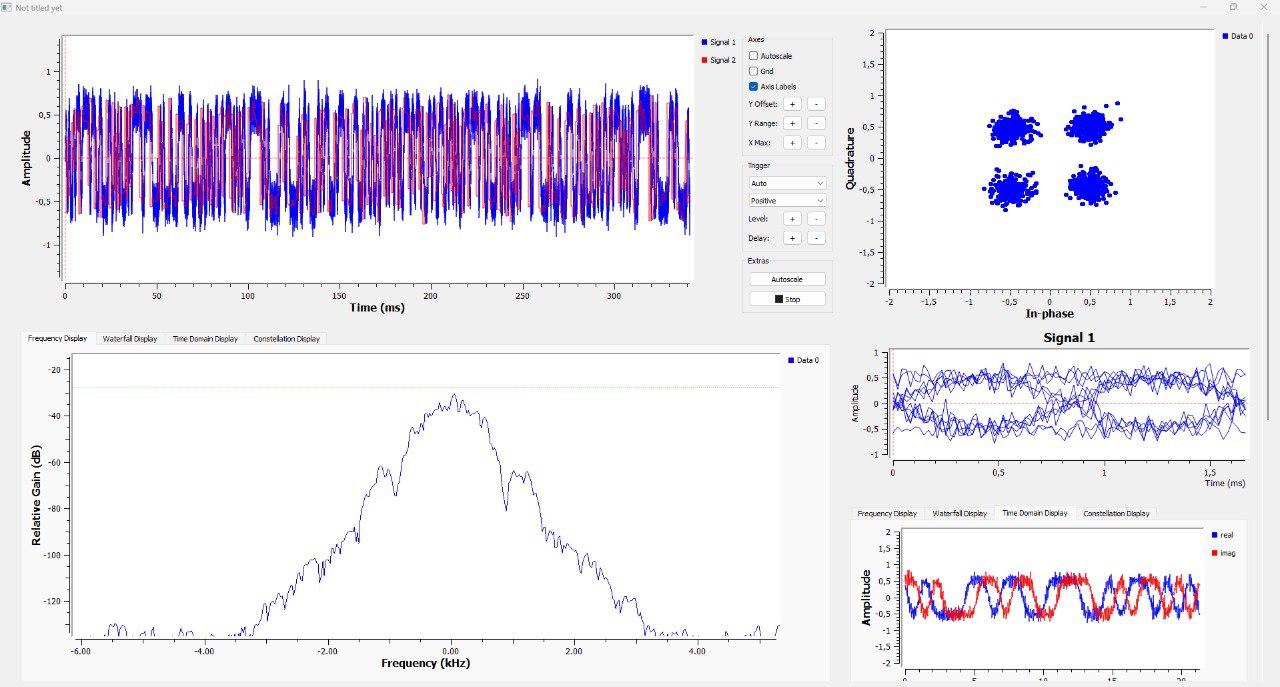
GMSK Modem with 0.5 BTb, 1200bd bitrate, 40x Oversampling simulated with 20dB SNR.
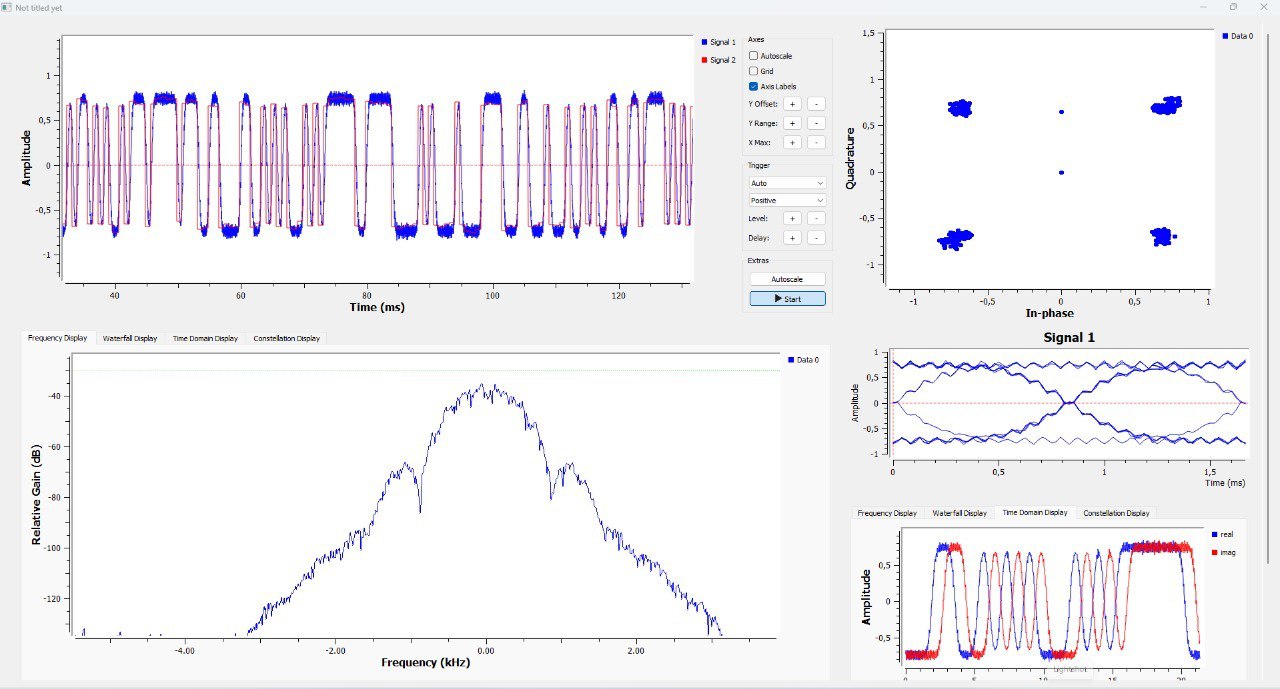
Modem GMSK com 0,5 BTb, taxa de bits de 1200bd, sobreamostragem de 40x simulada com SNR de 20dB.
A Arquitetura
Eu queria “Pipeline” os estágios do Modem de uma forma semelhante à forma como GnuRadio e alguns outros softwares SDR funcionam, tendo cada etapa (Filtragem, Modulação FM, etc) em um “Bloco” separado com um thread trabalhador (“worker”) sendo executado simultaneamente. Isso é um pouco complicado de implementar e provavelmente não estou fazendo certo, dicas são bem-vindas e você pode encontrar o código no GitHub.
Os blocos são derivados da classe base Block<IT, OT> e substituem a função virtual work(...), IT é o tipo de entrada e OT é o tipo de saída. Cada bloco possui ponteiros para objetos Stream<T>, cada um contendo um objeto Circular Buffer<T> e alguma lógica de sincronização de thread.
Aqui está uma visão simplificada da classe Block:
template<typename IT, typename OT>
class Block<IT, OT>
{
public:
Block(const size_t& BufferSize){...}
void start(){...}
virtual size_t work(size_t const size_t& n_inputItems, std::vector<IT>& input, std::vector<OT>& output) {...}
void stop(){...}
template <typename X>
void connect(Block<X,IT>& Other)
private:
Stream<IT>* InputStream;
Stream<OT>* OutputOutput;
std::thread worker;
};
O trecho de código acima mostra uma visão simplificada da classe Block, você pode ver que temos algumas funções:
Block(const& size_t BufferSize)
Este é o construtor da classe, ele recebe um const size_t&, basicamente um número inteiro sem sinal (unsigned), muito grande, BufferSize que é usado para alocar os buffers das streams de entrada e saída.
start()
Esta função é usada para iniciar os objetos Stream<T> internos do bloco, ela também inicia o thread worker que chama a função work em um loop alimentando-o com novas amostras do Stream de entrada e encaminhando-as para a Stream de saída.
stop()
Como você adivinhou, esta função interrompe os Streams e se junta (join) ao thread de trabalho. A thread espera que algumas condições sejam verdadeiras antes de sair, talvez isso possa ser melhorado tendo um parâmetro force que força a saída (exit) da thread…
connect(Block<...>& Other)
Connect é usado para vincular 2 blocos definindo o ponteiro InputStream do bloco atual (this) para o ponteiro OutputStream do bloco Other. Olhando para o trecho de código, você verá que o tipo de entrada Other não está definido, enquanto o tipo de saída deve ser o mesmo que o tipo de entrada this.
O uso é algo como:
Block<IT, float> A(1024); // A tem entrada do tipo IT e saída de ponto flutuante (float)
Block<float, T> B(1024); // B tem entrada do tipo float e saída T
B.connect(A); // Conexão (float) B <- A
O problema
Ao usar vários threads que acessam e modificam um recurso compartilhado, os objetos Buffer<T> neste caso, devemos sincronizar as leituras e gravações garantindo que os threads não entrem em Race Conditions e DeadLocks. As condições de corrida (“Race Conditions”) acontecem quando 2 threads tentam modificar o mesmo recurso, por exemplo, Thread-0 tenta gravar no buffer enquanto, ao mesmo tempo, Thread-1 tenta ler do buffer causando comportamento indefinido… DeadLocks acontecem quando 2 threads co-dependentes estão aguardando que algum recurso compartilhado seja liberado.
Idealmente, você usaria um buffer circular baseado em atômico (atomic) sem bloqueio e sem espera para obter o rendimento máximo sem esperar por variáveis de condição, bloquear e desbloquear mutexes (exclusão mutua), etc. threads usam variáveis de condição para esperar que a entrada seja preenchida com dados. Discutirei como decidi implementar isso no tópico a seguir.
Uma solução possível
Depois de muita pesquisa online, e xingando o ChatGPT LOL, encontrei algumas soluções que funcionaram parcialmente, acabei usando a abordagem “Canal” ou “Stream” como chamo. Isso foi baseado em uma resposta do StackOverflow. A ideia principal é ter um objeto Stream<T> compartilhado que contenha uma condition_variable, um mutex e o objeto Buffer<T>.
O mutex e a variável condicional (condition_variable) são usados para sincronizar as 2 threads que compartilham o Stream, enquanto o acesso ao buffer é feito através das funções writeToBuffer() e readFromBuffer() que recebem uma referência a um objeto vector<T> usado para armazenar os dados que serão passados de e para a função de trabalho e uma variável size_t representando o número de itens a serem lidos ou gravados no vetor de dados. Existem também funções open() e close() que são usadas principalmente para sinalizar aos threads de bloco se o stream está disponível ou não, isso é usado para encerrar os threads quando o stream está vazio e fechado.
Código simplificado mostrando a classe Stream<T>:
template <typename T>
class Stream {
private:
Buffer<T> buffer;
std::mutex m_mtx;
std::condition_variable m_cv;
public:
Stream(const size_t& Buffersize) {...}
void open() {...}
void close() {...}
void writeToBuffer(const std::vector<T>& data, size_t N) {...}
size_t readFromBuffer(std::vector<T>& data, size_t N) {...}
};
writeToBuffer()
A função adquire um bloqueio para o mutex e grava N itens do vetor de dados no objeto Buffer interno, após isso notifica a variável condicional (condition_variable) e libera o bloqueio. O próximo thread está aguardando esta variável de condição e começa a ler os dados após ser notificado.
readFromBuffer()
A função adquire um bloqueio para o mutex e tenta ler N itens do objeto Buffer interno no vetor de dados, após isso notifica a variável condicional (condition_variable) e libera o bloqueio, o valor de retorno é o número de itens lidos. O thread espera na variável condicional (condition_variable) até que a entrada não esteja vazia e começa a processar os dados após ser notificado.
Stream(const& size_t BufferSize)
O construtor Stream também recebe uma variável size_t encaminhada para o objeto interno Buffer<T>, sobre os Buffers eles também são uma implementação de buffer circular muito básica com métodos read() e write() não sincronizados que push e pull 1 item por chamada agrupando os índices de leitura e gravação quando eles forem maiores que o tamanho do buffer.
A principal vantagem dos buffers circulares é que os 2 threads que acessam o buffer podem escrever e ler sequencialmente, como um objeto Queue ou FIFO, a diferença é que depois que o buffer está cheio, ele apenas se sobrescreve, o estado vazio acontece quando o índice de leitura é o igual ao índice de escrita, o que significa que todas as entradas foram consumidas.
No trecho abaixo está uma visão geral simplificada da classe Buffer<T>:
template <typename T>
class Buffer
{
public:
Buffer();
Buffer(const size_t& BufferSize);
void resize(const size_t& BufferSize);
void write(const T& sample);
T read();
bool isEmpty(){
return m_head == m_tail;
}
bool isFull(){
return ((m_head+1) & m_mask) == m_tail;
}
~Buffer();
private:
size_t m_head;
size_t m_tail;
size_t m_size;
size_t m_mask;
std::unique_ptr<T> m_buffer;
size_t m_occupancy;
};
Vou apenas dar uma visão geral dos detalhes desta classe, já que muitas implementações de ring buffer estão disponíveis online e esta não tem nada de especial, é até um pouco abaixo do ideal.
Buffer()
Este é um construtor padrão e não tenho certeza se é necessário, apenas define tudo para zero.
Buffer(const size_t& BufferSize)
O construtor principal da classe onde o unique_ptr
resize(const size_t& BufferSize)
Esta função foi usada anteriormente para redimensionar o buffer que foi criado usando o construtor padrão, provavelmente será removido posteriormente…
write(const T& sample)
Isso grava um item no buffer e registrará um erro ao substituir o buffer quando ele estiver cheio.
read()
Assim como write() ele lê um item do buffer e registra um erro retornando um T() vazio se o buffer estiver vazio.
isEmpty() and isFull()
São usados para verificar se o buffer está vazio ou cheio, verificando os índices de leitura e gravação, eles retornam um bool definido como true se alguma das condições for atendida.
~Buffer()
O destruidor apenas registra uma string de depuração mostrando que o buffer foi destruído.
O formato de saída atual
Estou usando arquivos WAVE .wav para gerar os dados de QI do modulador (arquivo wav de 2 canais) e algumas das saídas do demodulador como as saídas do bloco FM Demod e TimingPLL. Nenhuma biblioteca foi usada para isso, pois o formato PCM WAVE descompactado de 16 bits é bastante simples, contém um cabeçalho, implementado como uma estrutura, e uma matriz de int16 representando os dados assinados.
Não há nada de especial na escrita dos arquivos e vou mostrar um trecho abaixo de como isso é implementado… Adicionei alguma lógica para detectar clipping, ou seja, amostras acima do nível máximo, e corrigindo para isto.
struct WavHeader{
#pragma pack(push, 1) // Compiler directive -> no padding between the variables...
/* RIFF CHUNK */
U32 RIFF_ID = 0x46464952; // "RIFF"
U32 RIFF_SZ = 0x00000000; // FileSize - 8
U32 RIFF_TY = 0x45564157; // "WAVE"
/* FMT CHUNK*/
U32 FMT_ID = 0x20746D66; // "fmt"
U32 FMT_SZ = 16; // Chunk size
U16 ComprCode = 1; // Compression Code
U16 NChans = 1; // NChannels
U32 SampleRate = 48000; // Sample Rate
U32 ByteRate = 96000; // Byte Rate = SampleRate * BlockAlign
U16 BlockAlign = 2; // BlockAlign = NChannels * BitsDepth/8
U16 BitDepth = 16; // BitDepth
/* DATA CHUNK */
U32 DATA_ID = 0x61746164; // "data"
U32 DataSize = 0x00000000; // Data size
/* PCM DATA */
#pragma pack(pop)
};
void WriteWav(std::string filename, std::vector<F32> data, size_t SampleRate=48000, int Channels=1, float scale=1.0f){
LOG_INFO("Writing Wav");
LOG_TEST("Path: {}",filename);
LOG_TEST("SampleRate: {}",SampleRate);
LOG_TEST("Channels: {}",Channels);
LOG_TEST("Data Size: {}",data.size());
/* File gets closed when std::ofstream goes out of scope */
std::ofstream outFile(filename, std::ios::binary);
/* Wav header (16 Bit Signed PCM Samples) */
WavHeader hdr;
hdr.NChans = Channels;
hdr.SampleRate = (U32)SampleRate;
hdr.BitDepth = 8 * sizeof(I16);
hdr.BlockAlign = Channels * hdr.BitDepth/8;
hdr.ByteRate = hdr.SampleRate * hdr.BlockAlign;
hdr.DataSize = (U32)data.size() * hdr.BitDepth/8;
hdr.RIFF_SZ = hdr.DataSize + sizeof(hdr) - 8;
// Write Header (44 bytes)
outFile.write((char*)&hdr, sizeof(hdr));
size_t nclip = 0;
// Write Data
for (size_t i = 0; i < data.size(); i++)
{
F32 Isample = data.at(i) * scale * (float)INT16_MAX;
if(std::abs(Isample) > (float)INT16_MAX){
Isample *= 1.0f/Isample;
nclip++;
}
I16 sample = (int)(Isample); // Convert FP32 -> S16
outFile.write((char*)&sample, sizeof(I16)); // Write S16 as 2 char's
}
if(nclip > 0){
LOG_ERROR("Clipping {} samples...",nclip);
}
}
A maior parte do código é a função WriteWav, ela escreve o arquivo wave e recebe um vetor de floats, alias F32, com os dados já intercalados no caso de múltiplos canais. A estrutura WavHeader é composta principalmente de constantes seguindo a especificação.
Também criei uma “biblioteca” de registro (loging) simples, é cabeçalho apenas na verdade, com algumas macros que imprimem informações no terminal usando std::format do C++20. As macros disponíveis são LOG_INFO, LOG_DEBUG, LOG_TEST e LOG_ERROR que são impressas em stdout. Cada macro recebe uma string de formato e seus argumentos através do argumento de macro VA_ARGS e imprime com uma cor diferente usando códigos de escape ASCII, há um exemplo de log abaixo.
Na próxima postagem...
No próximo post mostrarei como o modulador foi implementado, mergulhando no código dos blocos! Haverá também uma explicação mais detalhada da modulação GMSK e algumas das opções de design deste modem. Originalmente, eu queria ter tudo em um único arquivo C++, mas dividir o modem em um arquivo principal e uma biblioteca parece mais flexível, pois os blocos podem ser usados para criar outros tipos de modems…
Aqui está uma prévia do conteúdo do próximo post…
Bytes (Bytes do pacote)
↓
Bits (Bits do pacote)
↓
CCSDS Scramble (Embaralhameno)
↓
Repeat (Repete os bits)
↓
Gaussian Filter (Filtro Gussiano)
↓
FM Modulation (Modulção FM)
↓
Interpolation (Interpolação)
↓
Wav output (Saída em arquivo wav)
class Modulator
{
public:
Modulator(size_t BaudRate=1200, size_t SampleRate=48000, size_t BufferSize=4096);
void start(){...}
void sendPacket(...) {...}
void modulate(Stream<U8>& input_stream, bool scramble=false) {...}
void stop(){...}
private:
Stream<F32> m_inp_stream;
Stream<CF32>* m_out_stream;
FirFilter<F32>* m_Gfilter;
FirFilter<CF32>* m_interpolator;
FmModulator* m_fmmod;
};
Obrigado por ler! Espero que tenham gostado do conteúdo e continuem lendo os próximos posts desta série. Tchau!